
“切勿错过AI的决定性时刻”这句 NVIDIA GTC 的广告语自周三起,一时间传遍全网。依照惯例,大会由熟悉的面孔黄仁勋围绕AI、芯片等科技,发布了一系列前沿技术产品。
今年幻方 AI 再度受邀,在 NVIDIA GTC 2023 大会中进行了一次技术主题分享。

自 2019 年起,我们为了满足自己科研作业的大规模算力需求,逐步构建了幻方萤火深度学习智算平台,其包括存储网络相关基础设施、分时调度算法、以及深度优化的 hfai 框架。在实际的工作中,我们常常遇到很多模型训练与落地的挑战,本次讲座分享的内容就是过去一段时间,我们在软件和硬件上,取得的一些突破以及积累的相关解决方案。

以下是本次 GTC 主题分享的内容概要,也是我们阶段性的最佳实践。
FFRecord
目前网上的开源文件格式,比如 TFRecord 等在不需要随机访问样本的情况下能够获得优秀的性能;但在很多机器学习的场景下,用户训练模型时每一步需要随机采样多个样本。为此,我们专门设计了 FFRecord (Fire Flyer Record) 文件格式,帮助用户更加方便地享受 3FS 高速存储批量读取带来的效率提升。同时我们实现了和 PyTorch 完全兼容的接口,方便用户的迁移和加速。
用 ImageNet 性能测试显示,用 FFRecord 能够比大量小文件读取的 Pytorch dataloader 性能提升近 40%。不仅如此,为了方便用户在萤火集群上的训练,我们构建以 FFRecord 为基础的幻方 AI 数据集仓库。目前数据集仓库里已收纳了 20 多种大规模公开数据集,近 120 多个用户私有数据集。

hfai.nn
幻方 AI 对 Pytorch 框架进行了深度优化,结合幻方萤火集群的特点,对一些常用的 AI 算子重新研发,提升效率,进一步提升了模型整体的训练效率。

更快。为了让模型计算得更快,我们通过优化 CUDA kernel,融合多运算,优化模型结构等,使得深度学习算子计算更高效。

更省。现代模型越来越大,在不改变精度的情况下,我们通过压位等技术,在训练时减少了部分常用函数中间变量的内存,大幅节省训练的内存占用。
haiscale
随着模型规模和数据规模的扩大,越来越多的模型训练都要在多机多卡上进行。因此并行训练中的优化至关重要。Haiscale 是一个轻量级的高性能并行训练工具,集成了幻方 AI 多年的并行训练研发经验,能很轻松地兼容 PyTorch 进行并行训练提速,其包含:haiscale.ddp, haiscale.fsdp, haiscale.pipline 三大套件,它们都以幻方自研的 hfreduce 多机多卡通信方案为底座,进行并行训练的加速。

haiprof
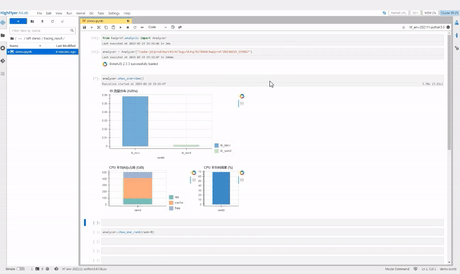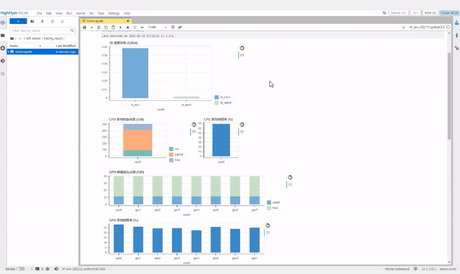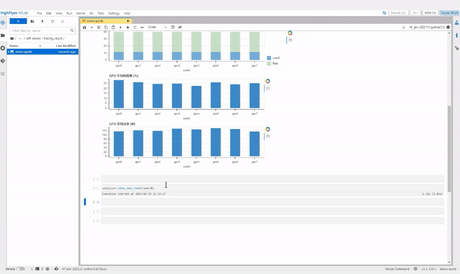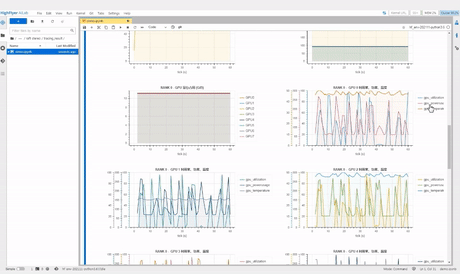
haiprof (High-flyer’s AI Profile) 是一个针对 PyTorch 模型的性能分析工具,用户能够在无需修改代码的情况下分析模型性能瓶颈,能随时调用,为整个训练过程做全方位的“CT”。
在任务运行的过程中,haiprof 会收集以下信息:
- CPU/GPU 利用率、功率、内存占用
- 用户读写流量、IB 流量
- 内存带宽、跨 NUMA 带宽
- forward、backward、optimizer、dataloader 的耗时
haiprof 还支持对 PyTorch 代码进行更深入的 tracing,分析不同函数、算子的时间开销。
自研路由算法
对于影响深度学习训练快慢的因素,人们常常容易忽略网络传输在训练提速中的重要作用。特别是在大规模集群,分布式训练的场景中,网络的拥塞可能直接导致 GPU 算力的失效,就像空有一段段双向 8 车道的快速路,但如果道路规划凌乱,高速路也只能沦为大型停车场。
在实际的应用中,我们便发现网络拥塞无处不在。而自研路由算法,帮助我们突破了传统的 fattree 架构,带我们来到了更加广阔的世界。
- 这一算法,能够支持我们多台大型 800 口互联,集群算力的提升突破了物理上传统 fattree 的上限;
- 支持我们使用同一个网络来支持存储和互联,大大降低了集群搭建的成本,提升了可维护性,增加了稳定性;
- 我们能够在原有典型 fattree上,构建其他低速子树,支持其他的异构运算节点,让所有节点都有各自需要的互联能力,提高了平台算力的多样性。
